7 · KV Cache Optimization: Your Most Under-Used Lever
Two systems running the same model on identical hardware can differ significantly in effective throughput based solely on KV cache strategy. This is where naive deployments diverge most from optimized production systems - and where the highest-leverage gains require no hardware changes.
7.1 PagedAttention: The Foundation
Before PagedAttention, serving systems allocated a single contiguous block of GPU memory per request at admission time, sized for the maximum possible output length. The problem is fundamental: output length is unknown when a request arrives. If the system's maximum context is 8K tokens and a request generates only 200 output tokens, 97% of its reserved memory sits locked and empty for the entire request lifetime - not reusable by any other request until that request fully completes. The vLLM paper reports that earlier systems utilized only 20-38% of allocated KV cache memory as a result. Not because the GPU lacked memory, but because the allocator held it hostage in large, mostly-empty reservations.
Think of it like a restaurant that assigns an eight-seat table to every party regardless of size. A couple gets a table for eight, six seats sit empty all evening, and the next party waits at the door even though the room is technically "full." The seats exist - they are just not usable.
PagedAttention fixes this by borrowing the virtual memory paging concept from operating systems. Instead of one contiguous slab per request, the KV cache is divided into small fixed-size blocks - 16 or 32 tokens per block in vLLM. A block table maps each request's logical token positions to physical GPU memory blocks, exactly like a page table maps virtual addresses to physical memory pages. Blocks from different requests are freely interleaved in physical memory. As a sequence grows it gets the next available free block regardless of physical location. When a request completes - or even when individual blocks are no longer needed - those blocks are immediately returned to the free pool at block granularity, not request granularity. That finer release cadence is the mechanism behind the 2-4× throughput improvement the vLLM paper reports on the same hardware.
Block size is a configuration tradeoff worth understanding. Smaller blocks - 16 tokens - reduce internal fragmentation: a request generating 17 tokens wastes only 15 tokens of padding rather than a full slab. But smaller blocks mean larger block tables and higher metadata overhead per request. Larger blocks - 128 tokens - reduce metadata overhead but increase fragmentation for short requests. The default of 16 tokens is right for mixed workloads with variable output lengths. Increase block size only for workloads with consistently long outputs where fragmentation is negligible and metadata overhead becomes the binding cost.
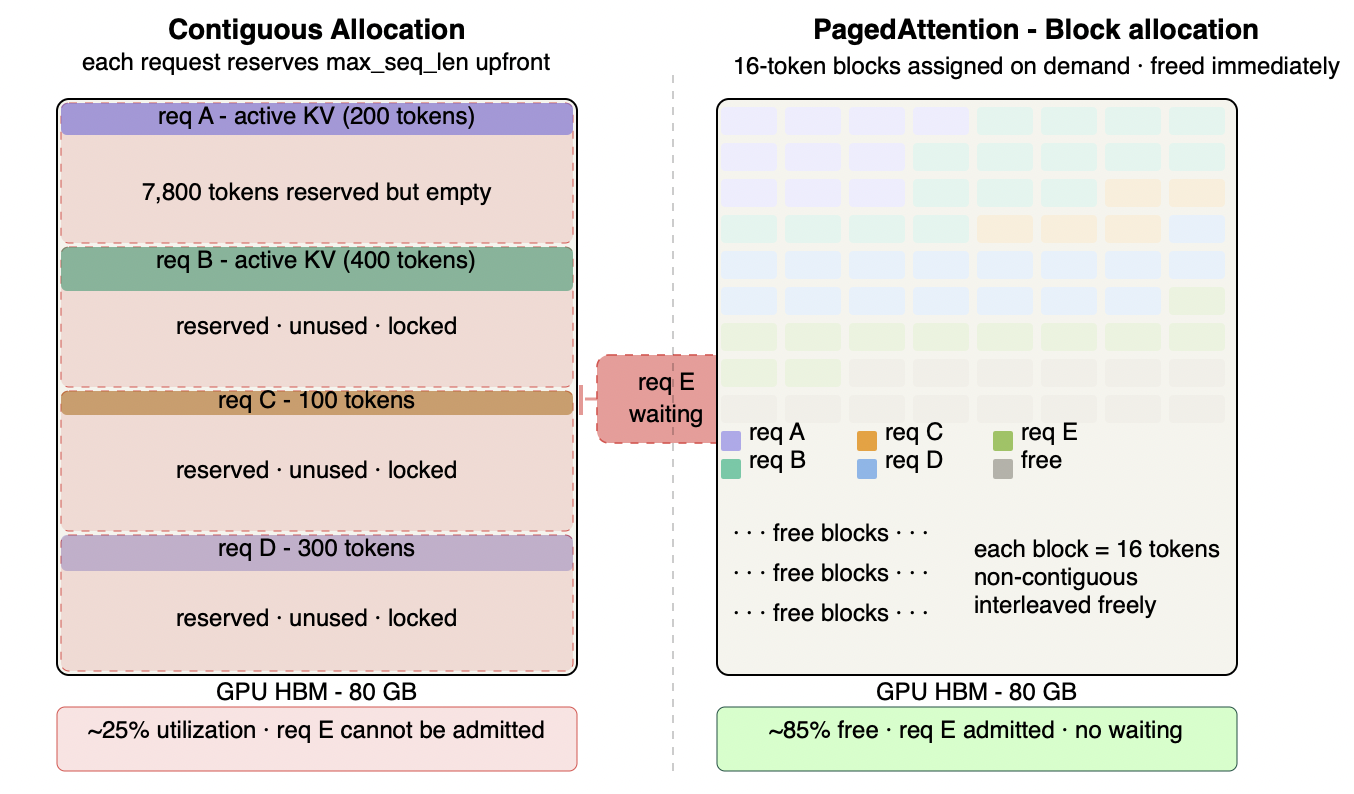
Figure 7.1 - PagedAttention: contiguous allocation vs block allocation
Left: each request reserves a full max_seq_len slab at admission. Four requests with short actual outputs hold 75%+ of GPU memory in empty reservations. Request E cannot be admitted despite most of the memory being physically free - it is just locked inside other requests' slabs. Utilization collapses to 20-38% under real workloads. Right: the same four requests occupy only the blocks they actually need - 16 tokens per block, non-contiguous, freely interleaved in physical memory. Request E is admitted immediately. Blocks are returned to the free pool the moment they are no longer needed, not when the entire request completes. The same GPU serves significantly more concurrent requests at near-full utilization.
One important constraint in distributed deployments. KV cache blocks are local to each GPU - there is no cross-GPU block pool. In a TP=4 deployment each GPU manages its own block allocator independently. This means the KV cache bottleneck in a TP group is always the most memory-pressured GPU. If GPU 0 exhausts its block pool, the request stalls regardless of how many free blocks GPU 1, 2, or 3 still have. PagedAttention eliminates within-GPU fragmentation efficiently - it does not solve cross-GPU memory imbalance. This matters in practice for TP deployments serving long-context workloads where attention head sharding creates uneven KV pressure across GPUs.
PagedAttention also enables prefix sharing across requests: blocks covering identical prompt prefixes - a shared system prompt, a few-shot template - can be physically shared in memory rather than duplicated per request. This is the foundation that prefix caching builds on in Section 7.2.
PagedAttention is now the default KV cache management mechanism in vLLM, TensorRT-LLM, SGLang, and every serious production inference framework. It is not an optimization you enable - it is the baseline everything else in this section builds on top of.
7.2 Prefix Caching: The Most Under-Deployed Optimization
Many production workloads share large common prefixes across requests - system prompts, RAG retrieved context, few-shot examples, conversation history. Without prefix caching, the KV state for these tokens is recomputed on every single request, burning GPU compute and memory bandwidth identically on the hundredth request as on the first. It is the inference equivalent of recalculating the same spreadsheet from scratch every time you open it rather than saving the result.
Prefix caching stores the computed KV blocks for reusable token sequences and reuses them on cache hits. When an incoming request matches a cached prefix, those tokens skip the prefill computation entirely - their KV state is read directly from cache. The effective prefill cost drops to only the unique tokens in the request. For a RAG workload with a fixed 8K system prompt and 4K retrieved context, a cache hit means prefilling only the user's 50-token query rather than 12,050 tokens. TTFT drops proportionally. GPU compute is freed for other requests.
The cache hit rate is everything - and it is workload-dependent. Before deploying prefix caching, estimate your expected hit rate. The signal is in your request distribution:
If your workload has a fixed system prompt shared across all requests - a customer service bot, a RAG pipeline with a standard context template, a code assistant with a fixed few-shot preamble - your hit rate on that prefix approaches 100% regardless of query diversity. This is where prefix caching delivers its largest gains, often reducing effective TTFT by 60-80% on the shared portion.
If your workload has highly variable or unique prompts - creative writing, open-ended chat with no shared context - hit rates approach zero and prefix caching adds overhead without benefit. The cache lookup cost is small but not free.
Multi-turn conversation history is the middle case. The system prompt is always cached. Each turn extends the cached prefix by one exchange. Hit rates on the accumulated history depend on how consistently the same conversation lands on the same instance - which is a routing problem covered in Section 7.3.
Two implementation approaches with different tradeoffs. vLLM uses hash-based exact prefix matching - the entire prefix token sequence is hashed and looked up in the cache. This is simple and fast but only matches requests that share an identical prefix from the start. SGLang implements a radix tree structure that enables partial prefix matching - any shared prefix length produces a cache hit, not just full-prefix matches. For workloads where requests share a system prompt but diverge in the retrieved context, radix tree matching captures partial hits that hash-based matching misses entirely. If your framework supports it, radix tree prefix caching is strictly better for mixed workloads.
The memory tradeoff must be sized explicitly. Prefix caching consumes KV cache blocks to store cached prefixes. Those blocks are unavailable for active request KV state. At high cache utilization, the LRU eviction policy begins evicting cached prefixes to make room for active requests - which reduces hit rates precisely when the system is under the highest load. The practical sizing rule: allocate at least 20-30% of your KV cache budget to prefix storage beyond what active request concurrency requires. Monitor both cache hit rate and eviction rate as production metrics - a rising eviction rate under load signals that your prefix cache budget is too small for your traffic pattern.
In a single-instance deployment, prefix caching is straightforward - one cache, all requests hit it. In a multi-replica deployment behind a load balancer, the same request may land on different replicas with cold caches, eliminating the hit rate benefit entirely. That is the problem Section 7.3 addresses.
7.3 Cache-Aware Routing: Single-Instance vs Multi-Replica
Prefix caching only delivers value if requests land on replicas that already hold the relevant KV state. In a naive round-robin setup, requests are distributed evenly across replicas regardless of content - which dilutes cache locality and collapses hit rates to roughly 1/N where N is the replica count. A perfectly configured prefix cache on each replica produces near-zero aggregate benefit if routing sends each request to a different one.
Cache-aware routing restores locality by routing requests based on their prefix - so that repeated or similar inputs consistently land on the same replica. After the first request warms a replica's cache for a given prefix, every subsequent request for that prefix hits without recomputation. The 4K-token RAG context prefill is paid once and amortized across all subsequent requests. This is not a marginal improvement - it is the difference between a cache hit rate of ~25% under round-robin and ~90%+ under prefix-hash routing for workloads with high prefix overlap.
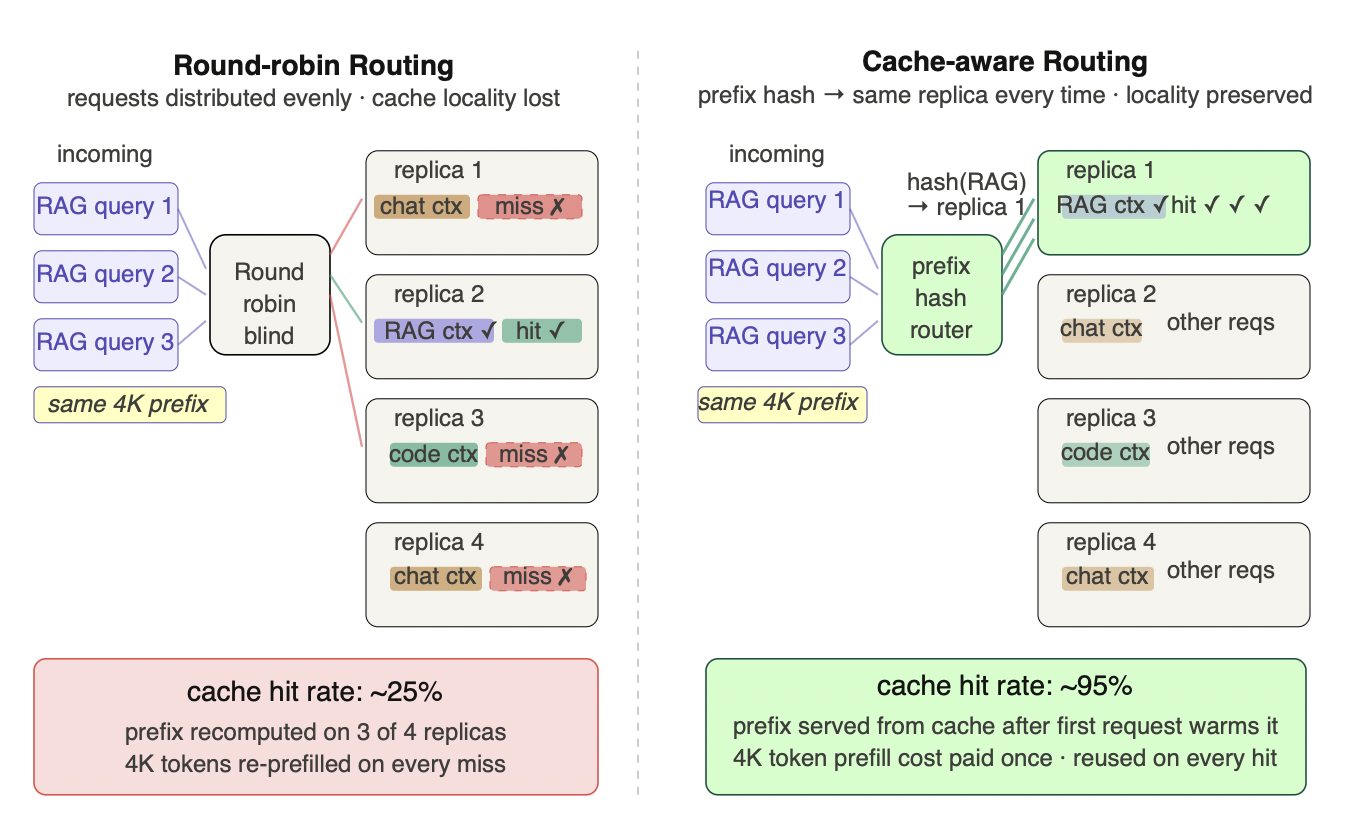
Figure 7.3 - Cache-aware routing: why round-robin kills your cache hit rate
Left: round-robin distributes three requests with identical 4K-token RAG prefixes across four replicas. Each replica holds a different cached prefix - only replica 2 happens to hold the RAG context. Two of the three requests miss, recomputing 4K tokens of prefill from scratch. Hit rate collapses to ~25% regardless of how well the cache is configured. Right: a prefix-hash router computes a deterministic hash of the shared prefix and always routes RAG queries to replica 1. After the first request warms the cache, every subsequent request hits. The 4K prefill cost is paid once and amortized across all requests. The key insight: prefix caching and cache-aware routing are not independent optimizations - one without the other delivers most of neither. This is the most commonly overlooked gap between single-instance benchmarks and multi-replica production deployments.
A note on the routing implementation.
The simplest way to route by prefix is: hash the prefix, divide by the number of replicas, send to that replica - replica = hash(prefix) % N. This works until you add or remove a replica. When N changes from 4 to 5, a prefix with hash value 17 that previously went to replica 1 (17 % 4 = 1) now goes to replica 2 (17 % 5 = 2). This is not just one prefix - mathematically, only about 1 in N prefixes will accidentally land on the same replica after the change. The other (N-1)/N of your prefixes remap simultaneously, every affected replica starts cold, and you get a fleet-wide cache miss storm during what should have been a routine scaling event.
Consistent hashing avoids this by placing both replicas and prefixes on a fixed ring rather than using replica count as the divisor. Each prefix routes to the nearest replica clockwise on the ring. When you add a new replica, it takes a position on the ring and absorbs only the prefixes between it and its neighbor - roughly 1/N of traffic. Everything else stays exactly where it was. Cache hit rates dip briefly for a small fraction of traffic rather than collapsing across the entire fleet.
Before relying on prefix caching in a multi-replica deployment, verify that your serving framework uses consistent hashing for prefix routing - not simple modulo. The distinction is invisible until your first autoscaling event, at which point it becomes very visible very quickly.
The load balance tension is the core design tradeoff.
Prefix-hash routing concentrates traffic - all requests sharing the same popular prefix route to the same replica. For a RAG deployment where 80% of requests share a common system prompt, prefix-hash routing sends 80% of traffic to one replica. That replica becomes a hotspot: memory pressure rises, queue depth grows, and latency degrades precisely for the most common request type. The solution is a hybrid policy - use prefix-hash routing as the primary signal, but cap any single replica's load share and overflow excess traffic to the next available replica. SGLang's cache-aware load balancer implements this with a configurable load threshold; llm-d's router uses a similar overflow mechanism. The threshold is a tunable tradeoff between cache locality and load balance - set it too high and you get hotspots, too low and you sacrifice hit rates.
The cold start problem during scaling and restarts.
When a new replica comes online or an existing one restarts, its cache is cold. Prefix-hash routing immediately sends all matching traffic to that cold replica, producing a burst of cache misses and prefill compute spikes that can briefly saturate the new replica's GPU. Production deployments handle this in two ways: gradual traffic shifting - ramping the new replica from 0% to full share over several minutes to allow the cache to warm under controlled load - or cache seeding, where a peer replica transfers its most frequently accessed prefix blocks to the new replica before it begins receiving traffic. Neither is complex to implement, but both require explicit operational handling that most teams discover only after their first scaling incident.
Prefix caching and cache-aware routing are not independent optimizations. One without the other delivers most of neither. Single-instance benchmarks that show large prefix caching gains will not replicate in multi-replica production unless routing is configured to preserve locality. This is the most commonly overlooked gap between benchmark results and production outcomes for this optimization.
7.4 KV Cache Eviction: Managing Memory Pressure
Prefix caching and cache-aware routing maximize what you keep in the KV cache. Eviction policy determines what happens when you run out of space to keep it - and the wrong policy for your workload pattern can silently undermine everything the previous two sections built.
KV eviction operates at two distinct levels in production: prefix-level eviction, which governs what survives across requests, and token-level eviction, which governs what survives within a single request's generation. Understanding both is necessary because they address different problems, carry different quality risks, and interact differently with other optimizations in your stack.
Prefix-Level Eviction - What Stays in the Cache Across Requests
When the prefix cache fills, the serving system must decide which cached KV blocks to keep and which to discard. Three policy families cover most production scenarios.
LRU - Least Recently Used is the default in vLLM, SGLang, and most production frameworks. The rule is simple: when space is needed, evict the prefix that was accessed least recently. Think of it like a desk where you keep the documents you touched most recently on top and sweep the oldest ones into a drawer when the desk fills up.
LRU works well for diverse, unpredictable workloads where no single prefix dominates traffic and reuse patterns are irregular. It requires no configuration and degrades gracefully as traffic patterns shift.
Where LRU fails is workloads dominated by a small set of high-frequency prefixes. Consider a RAG deployment where 80% of requests share the same 8K-token system prompt. Under bursty diverse traffic, that system prompt can slide to the bottom of the recency queue and get evicted - forcing recomputation of 8K tokens for the next request that needs it, which is immediately. LRU does not distinguish between "this was accessed 10 seconds ago by 1 request" and "this was accessed 10 seconds ago by 1,000 requests." Recency and frequency are different signals, and LRU only tracks one of them.
Frequency-based eviction fixes this by tracking how often each prefix has been reused and protecting the most frequently accessed ones regardless of when they were last accessed. The rule: when space is needed, evict the prefix that has been reused the fewest times overall, not the one that was accessed least recently.
This is the right policy when a small set of prompts - a shared system prompt, a fixed RAG context template, a few-shot preamble - accounts for the majority of your traffic. Those high-frequency prefixes stay permanently resident regardless of recency fluctuations.
Where frequency-based eviction fails is highly diverse workloads where no prefix repeats more than once or twice. With no meaningful frequency signal to act on, the policy degrades toward random eviction behavior and adds bookkeeping overhead without benefit. If your workload's prefix reuse distribution is flat, LRU is the better default.
Priority-based eviction takes a different approach entirely - instead of evicting based on recency or frequency, it protects in-flight and recently active sessions from eviction regardless of their statistical rank. When space is needed, lower-priority background prefixes are evicted first and active session context is preserved.
This matters most for multi-turn conversational deployments. If a user is mid-conversation and the decode instance evicts their conversation history to make room for a new request, the user's next message must recompute the entire conversation from scratch. That recomputation adds latency that is directly user-visible - the model appears to stall before responding. Priority-based eviction prevents this by treating active session context as protected memory that yields only to other active sessions, never to background or cold prefixes.
The practical guidance: start with LRU as your default. If monitoring shows that your most frequently accessed prefixes are being evicted and recomputed repeatedly - you will see this as elevated prefill compute on requests that should be cache hits - switch to frequency-based eviction. Add priority-based protection for active sessions only if multi-turn latency degradation is measurable in your P99 metrics.
The Memory Pressure Cascade - What Actually Goes Wrong
Rising eviction rate is not a normal operating condition. It is an early warning signal for a failure mode that presents as a latency problem rather than a memory problem, which makes it genuinely difficult to diagnose without the right metrics.
Here is the cascade sequence. The KV cache fills. Eviction begins. Evicted active requests must either be swapped to CPU DRAM or recomputed from scratch when their next token arrives. If the eviction rate exceeds the recovery rate, requests queue behind their own evicted state. Queue depth rises. TTFT grows. GPU utilization drops because the GPU is waiting for recovery operations rather than doing useful work. From the outside, the system looks like it has a latency problem or a throughput problem - not a memory problem.
The practical threshold: eviction rates above 5-10% of active requests per second indicate your KV cache budget is undersized for current traffic. Above 20%, eviction overhead is materially degrading throughput and latency. Treat this as a capacity signal - either provision more KV cache budget, apply more aggressive KV cache quantization, or reduce concurrent load.
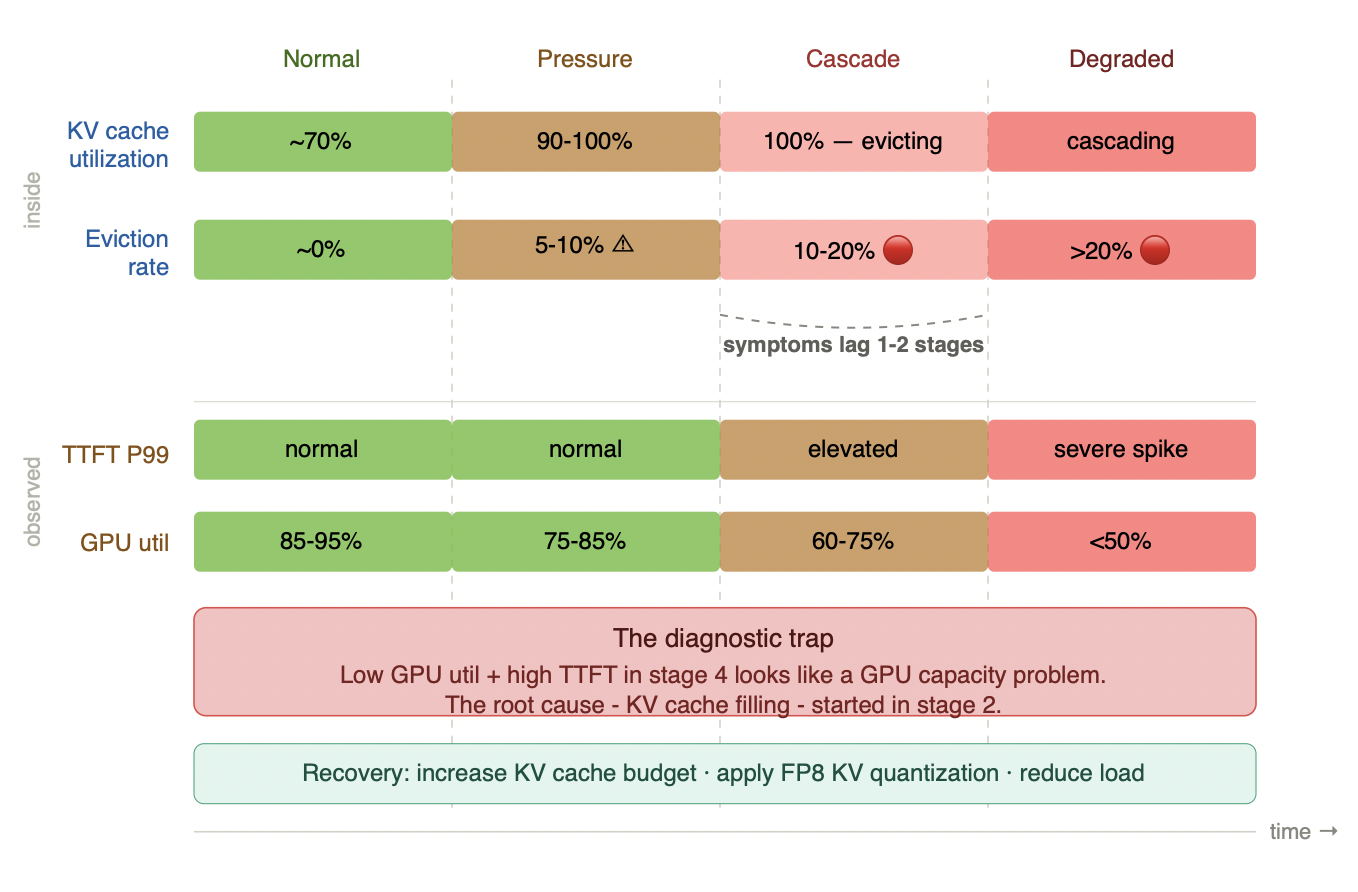
Figure 7.4 - The KV cache memory pressure cascade
The top two rows show what is happening inside the system - KV cache utilization and eviction rate both turn critical by stage 2. The bottom two rows show what is externally observable - TTFT and GPU utilization stay healthy through stage 2 and only degrade in stages 3 and 4. By the time your latency alerts fire, the root cause has been building for two stages. A system presenting as a GPU capacity problem in stage 4 almost always has a KV cache budget problem that originated in stage 2. Instrument eviction rate from day one - it is the only metric that fires early enough to intervene before the cascade reaches the observable layer.
Swap vs Recompute - The Recovery Decision
When an active request's KV state is evicted, the framework must choose between two recovery paths. This is a decision most teams leave at framework defaults without understanding the tradeoff.
Swapping to CPU DRAM preserves the full KV state by moving it off GPU memory to system RAM. When the request resumes, the KV blocks are transferred back via PCIe. This preserves output quality perfectly - the model sees the same KV state it would have seen without eviction. The cost is transfer latency: at PCIe Gen5 bandwidth of ~64 GB/s per direction, a 1 GB KV cache takes roughly 15ms to swap back. For long-context requests with large KV states, this is usually cheaper than recomputation.
Recomputing from scratch discards the evicted KV state entirely and reruns the prefill on the evicted tokens when the request resumes. This avoids the PCIe transfer but burns GPU compute proportional to the evicted context length. For short contexts - under a few hundred tokens - recomputation is typically faster than swapping. For long contexts - thousands of tokens - swapping is almost always the better choice.
vLLM implements both strategies with a configurable swap threshold. Most deployments should verify this threshold is tuned to their typical context length distribution rather than left at the default. If your workload is predominantly long-context, bias toward swapping. If it is predominantly short-context, recomputation is cheaper.
Eviction in Disaggregated Deployments - A Special Case
In a disaggregated prefill-decode deployment, eviction on decode instances has a consequence that does not exist in colocated systems. If a decode instance evicts a prefix that an incoming request needs, the request cannot recover locally - it must be sent back to a prefill instance for recomputation, adding a full prefill round trip to what should have been a decode-only operation. This breaks the disaggregation latency model for evicted sessions and can make P99 latency significantly worse than a colocated baseline for affected requests.
Two mitigations: first, provision decode instance KV cache budgets conservatively - size for active request concurrency plus a meaningful buffer for frequently reused prefixes, not just the minimum to fit active requests. Second, implement session pinning for active multi-turn conversations so their KV state is marked protected and does not participate in eviction until the session ends.
Token-Level Eviction - Reducing Memory Within a Single Request
Prefix-level eviction manages memory across requests. Token-level eviction manages memory within a single request's generation - selectively dropping individual token positions from the KV cache during generation based on estimated attention importance.
The motivation is the attention skew observation: in transformer models, a small subset of token positions consistently receives the majority of future attention mass. Most tokens, once generated a few steps ago, are rarely attended to again. Storing their full KV state wastes memory that could serve more concurrent requests.
SnapKV estimates which token positions are actively attended to based on recent attention patterns observed during generation and evicts the positions that fall below an attention threshold. It is adaptive - the set of protected positions updates as generation proceeds and the model's attention focus shifts.
H2O (Heavy Hitter Oracle) takes a cumulative approach, tracking total attention scores across all generation steps and permanently protecting the tokens that have received the highest cumulative attention mass - the "heavy hitters." Tokens that have never received significant attention across the entire generation history are candidates for eviction.
Both approaches reduce KV memory footprint meaningfully - reported reductions of 20-50% are realistic for long-context workloads - with quality degradation that is workload-dependent.
For conversational workloads where the model's attention is dominated by recent context and the task does not require retrieving specific information from early in the sequence, token-level eviction produces negligible quality loss. The evicted tokens genuinely are not contributing to the model's generation.
For long-context retrieval tasks - legal document analysis, long-form summarization, needle-in-a-haystack queries, agentic tool-call histories - the evicted tokens may contain exactly the information the model needs to retrieve later in generation. Quality degradation in these cases can be significant and task-specific. Always benchmark on your specific task and workload before enabling token-level eviction in production. The memory saving is real; so is the risk.
One compatibility issue that is not widely documented: token-level eviction modifies the KV cache structure by removing positions that the framework assumes are present. Speculative decoding's verification pass assumes the KV cache is a complete record of all prior token positions - if token-level eviction has removed positions that the draft model speculated against, the verification pass produces incorrect results. Do not combine token-level eviction with speculative decoding without explicitly verifying framework-level compatibility first.
Decision Sequence
The strategies above are not mutually exclusive - they layer on top of each other as your workload complexity and memory pressure grow. The table below maps the common scenarios to the right starting point and tells you exactly when to add the next layer.
| Scenario | Policy | Trigger to escalate |
|---|---|---|
| Default starting point, diverse unpredictable traffic | LRU prefix eviction | High-frequency prefixes appearing in prefill compute despite being recently cached |
| Small set of prompts dominates traffic (RAG, shared system prompt) | Frequency-based eviction | LRU eviction rate on your top-5 prefixes is measurable - they keep getting dropped and recomputed |
| Multi-turn conversational workload | + Priority-based eviction for active sessions | P99 latency spikes visible on conversation turns that should be cache hits |
| Eviction rate above 10% of active requests per second | Increase KV cache budget, apply KV cache quantization (Section 7.5), or reduce load | Eviction rate above 20% - system is in degraded state, not a normal operating condition |
| Disaggregated P/D deployment | Larger decode KV cache budget + session pinning | Any active session being evicted and sent back to prefill pool for recomputation |
| Long-context workload where KV cache dominates memory budget | Evaluate token-level eviction (SnapKV or H2O) | Only after quality validation on your specific task - do not enable speculatively |
| Running both token-level eviction and speculative decoding | Verify framework compatibility explicitly | Incompatible by default - token-level eviction removes positions speculative decoding assumes are present |
7.5 KV Cache Quantization: A Concurrency Lever
KV cache quantization appeared as a recovery lever in the previous section. It deserves its own treatment because it is not just an emergency response to memory pressure - it is a proactive capacity decision that changes the economics of your deployment before pressure ever builds.
It is also fundamentally different from weight quantization, and the difference matters operationally. Weight quantization reduces model size and compute cost permanently - it changes the model and affects every request's output quality in a fixed, measurable way. KV cache quantization reduces runtime memory consumption per active request, which directly converts saved memory into additional serving capacity. It does not change the model. It does not affect requests that fit entirely within the quantized cache without overflow. And unlike weight quantization, its quality impact scales with context length - short-context evaluations will not surface the degradation that long-context tasks may experience.
The memory math is the starting point. At FP16, Llama-3 70B generates approximately 0.26 MB of KV cache per token per request. At 50 concurrent requests with 4K-token contexts that is 52 GB - more than half an H100's 80 GB, leaving limited headroom for model weights and activations. FP8 KV cache halves this to 26 GB. Same hardware, same model, same concurrency target - but now you have 26 GB of recovered headroom that can either serve more concurrent requests or support longer contexts. At NVFP4 on Blackwell hardware the savings compound further to 13 GB for the same workload.
The three precision tiers and their tradeoffs.
FP8 KV cache is the production default on H100 and Blackwell and is supported in vLLM and SGLang. Quality impact is minimal for most workloads - empirically, short-to-medium context tasks show negligible degradation. The risk surface is long-context precision-sensitive tasks: legal document analysis, multi-hop reasoning over long context windows, and tasks where the model must retrieve specific information from early in a long sequence. In these cases, the reduced precision in stored key-value vectors can cause the model to attend to slightly different positions, producing subtly different outputs. Always run your specific long-context evaluation suite before declaring FP8 KV cache safe for production on precision-sensitive workloads.
NVFP4 KV cache, available on Blackwell hardware, halves memory again relative to FP8. The quality tradeoff is more pronounced and workload-dependent. On tasks dominated by recent context - conversational, short-output workloads - the degradation remains manageable. On tasks requiring precise retrieval from long histories, quality degradation becomes measurable. Treat NVFP4 KV cache as an aggressive capacity lever for latency-tolerant workloads where maximum concurrency is the primary objective, not a default setting.
KVQuant and similar research approaches apply non-uniform quantization tailored to the statistical distribution of KV tensors rather than fixed-precision formats. Because KV distributions are not uniform - certain attention heads and certain token positions carry disproportionately high information content - adaptive quantization can achieve lower effective bit-widths with less quality loss than naive FP8. These approaches are not yet standard in production frameworks but are worth tracking as they mature.
The composition property is significant. Because KV cache is fully independent of model weights, these optimizations stack cleanly. A deployment running FP8 weights can additionally apply FP8 KV cache quantization, compounding memory savings without any interaction between the two decisions. The total memory reduction from combining weight and KV cache quantization is additive - the two levers do not interfere with each other and do not require coordinated quality validation.
How to sequence the decision. Start with FP8 KV cache as the default on H100 and Blackwell - enable it, validate quality on your specific task distribution including your longest-context evaluation cases, and keep it on unless you find a specific failure mode. If you need more capacity beyond what FP8 provides, evaluate NVFP4 on Blackwell with a careful quality benchmark. If you are hitting the limits of what fixed-precision quantization can provide without unacceptable quality loss, KVQuant-style adaptive approaches are the frontier to watch.
KV cache quantization addresses the per-request memory footprint. The next lever - offloading - addresses a different constraint: what happens to requests whose KV state cannot fit in GPU memory at all, even after quantization.
7.6 KV Cache Offloading: Trading Latency for Capacity
KV cache quantization reduces per-token memory cost. At long enough context lengths, even quantized KV cache exceeds what GPU HBM can hold for the number of concurrent requests you need to serve. A 100K-token context on Llama-3 70B at FP16 generates roughly 8 GB of KV cache for a single request - at FP8 that is still 4 GB. On an 80 GB H100 with 70 GB consumed by model weights and framework overhead, you can serve exactly one such request before the GPU is full. At long context lengths, KV cache stops behaving like an ephemeral compute state and starts behaving like a dataset - large, structured, and only partially active at any moment.
This is architecturally distinct from the reactive swap discussed in Section 7.4. Eviction-driven swap is a pressure relief valve - it kicks in when the cache fills unexpectedly under load. KV cache offloading is a deliberate tiering decision made at deployment time for workloads where long-context capacity is a known, structural requirement.
KV cache offloading solves the capacity problem by treating GPU memory as the hot tier in a storage hierarchy. Active KV blocks stay in HBM. Blocks that are not immediately needed move to CPU DRAM or NVMe and are fetched back when attention requires them - the same way a database tiers hot and cold data across DRAM and SSD. The GPU's HBM budget is freed to serve more concurrent contexts rather than holding the full KV state of every active request simultaneously.
The cost is reload latency, and the math determines whether it is worth paying.
PCIe Gen5 delivers roughly 64 GB/s effective transfer bandwidth between GPU and CPU DRAM. That 8 GB KV cache takes approximately 125ms to reload from CPU DRAM. NVMe adds a second tier with higher latency - current enterprise NVMe sequential read bandwidth peaks at roughly 7 GB/s, meaning the same 8 GB KV cache takes approximately 1.1 seconds to reload from NVMe. That second tier is only viable for offline batch workloads with no interactive latency SLO.
Whether the CPU DRAM tier is acceptable depends entirely on your workload. For interactive chat, 125ms per cache miss adds visible jitter to token generation - the user sees a stall mid-response every time a block is fetched back. Offloading is the wrong tool for this use case. For batch summarization of long documents, 125ms is acceptable if it lets you serve four times more concurrent contexts on the same hardware - the throughput gain justifies the latency cost, and no user is waiting for individual tokens.
Mooncake - ByteDance's KV cache-centric disaggregated serving architecture - validates this pattern at scale, treating KV storage as a first-class distributed resource separate from compute and demonstrating meaningful throughput improvements in memory-bound regimes by putting otherwise idle CPU DRAM to work systematically rather than reactively.
The decision rule is straightforward. Reach for offloading when the alternative is rejecting requests entirely or OOM-evicting active sessions, and when your latency SLO can absorb the reload cost. For most interactive deployments, KV cache quantization or additional GPU memory is the right first move - both reduce memory pressure without adding reload latency. Offloading is the right answer for long-context batch workloads. It is not the default answer for general serving.
7.7 What to Measure in Production
The optimizations in this section - PagedAttention, prefix caching, cache-aware routing, eviction policy, quantization, offloading - are only as effective as your ability to measure whether they are working. KV cache failures are particularly insidious because they present as latency or throughput problems rather than memory problems. Without the right metrics, you will chase the wrong root cause. The goal is not just monitoring but diagnosis: each metric maps directly to a failure mode and a concrete action.
| Metric | What it Measures | Signal | Action |
|---|---|---|---|
| Cache hit rate | Fraction of prefill tokens served from cache vs recomputed | Low hit rate despite known prefix reuse indicates lost locality - missing prefix caching, insufficient cache size, or round-robin routing destroying locality | Enable prefix caching, increase cache budget, or implement cache-aware routing |
| Prefix cache reuse ratio | Fraction of total prefill compute avoided through caching | High hit rate but low reuse ratio means your cache is hitting on short prefixes that save little compute - the optimization is working but not on the right prefixes | Identify your longest shared prefixes and verify they are being cached and routed correctly |
| KV cache utilization | Fraction of allocated KV memory actively used | Low utilization → over-provisioning or fragmentation. Near 100% → memory-bound, risk of OOM or aggressive eviction | Tune allocation, enable PagedAttention if not already active, or apply KV quantization |
| Eviction rate | Frequency of cache entries dropped under memory pressure | Rising eviction under steady load means insufficient capacity or wrong eviction policy. Above 10% is a warning. Above 20% is a degraded state | Increase cache budget, switch eviction policy, or reduce footprint via quantization |
| KV residency time | How long entries stay in cache before eviction | Short residency with high reuse potential indicates cache churn - entries are being computed, cached briefly, evicted, and recomputed | Increase cache size or protect high-frequency entries with frequency-based eviction |
| KV transfer latency | Time to move KV blocks between tiers - GPU to CPU DRAM in offloading, prefill to decode node in disaggregation | Rising transfer latency in a disaggregated or offloaded deployment signals interconnect saturation, not GPU compute saturation | Check PCIe or network utilization - the bottleneck may be the data path, not the GPU |